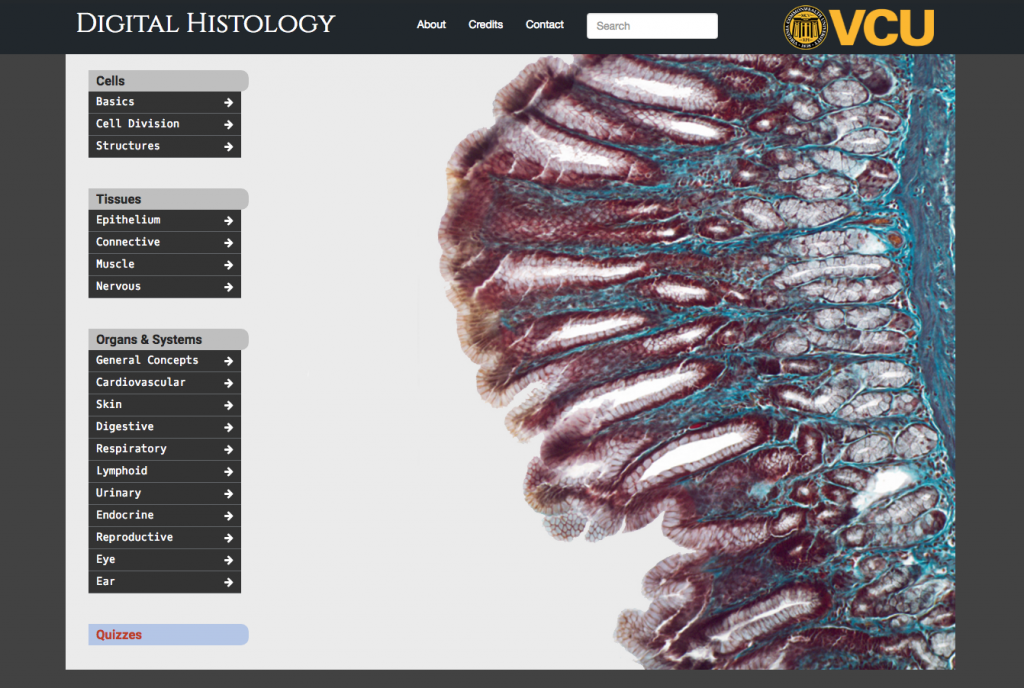
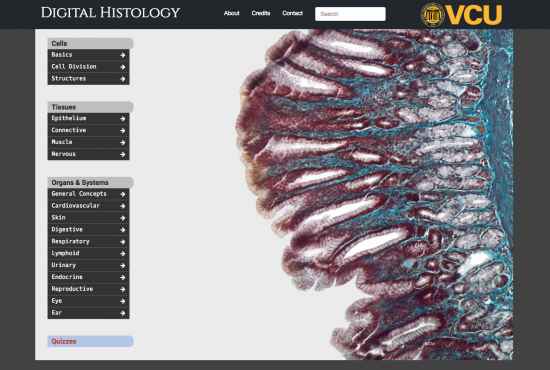
Normally we finish our projects in anywhere from a few hours to a few weeks. Digital Histology has been the exception to that rule. I can see a reference to the site going back to Nov. of 2016! That doesn’t mean we’ve worked on this site continuously for years. The gaps have been frequent and long. OER grants have been written and won. Presentations have been made. Work has ebbed and flowed as the massive amount of content has been entered. There are more than 1500 pages1 and over 5GBs of images. It’s a large site. A ton of work has gone into its construction, new goals have developed, and just about all of it is a little strange. 2 I figured I’d better document some of this before I forgot all of it.

The History
I don’t recall all the details but essentially long ago in a Macromedia Authorware galaxy far, far away a digital histology program was constructed. Time passed. Acorns grew into trees. WINE was now required to launch the digital histology program. The screen was a tiny 752×613. It only ran on desktops. Updating it was nearly impossible. Things were not good. After much wandering we found one another and endeavored to put this work online for the betterment of humankind.
Having a previous project did some good things for us — the content was mostly created and there was experience working with digital projects. The previous construction patterns in Macromedia were very different from the way building on the web works today. We did quite a bit of work to parallel the previous interactions. I don’t know if that’s how I would have done it had we started from scratch. This was also the first time I’d built anything substantial with ACF.
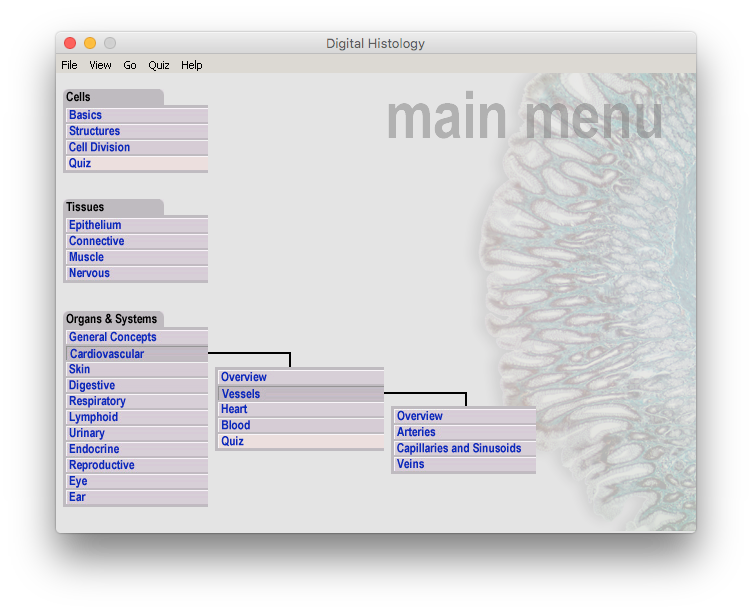
The Menu/Main Page
The menu has gone through a few iterations as we came up with different ways to deal with just how many pages were involved and how to deal with a really odd linking pattern. I’ll try to draw the menu pattern below. We had to figure out which pages had no grandchildren and for each one of those we would keep the title but link directly to the first child. Pages with no children would not be shown at all. Not super weird I guess but not normal.
To deal with the scale, Jeff wrote a slick little plugin to dump the pages data into JSON. That saves us a lot of time especially given the way that WordPress recursively builds menus. Jeff also had the layout generated in Vue.
/* Plugin Name: Menu Cache Plugin
* Version: 1.0.2
* Author: Jeff Everhart
* Author URI: http://altlab.vcu.edu/team-members/jeff-everhart/
* License: GPL version 2 or later - http://www.gnu.org/licenses/old-licenses/gpl-2.0.html
* Description: This is a helper plugin for developing complex menus. On post save, we cache all of the data for pages in a JSON file to be used on the front end.
*
*/
function create_menu($post_id) {
global $wpdb;
$results = $wpdb->get_results( "SELECT `ID`, `post_title`, `post_parent`, `post_name`, `guid` FROM {$wpdb->prefix}posts WHERE post_type='page' and post_status = 'publish' ", ARRAY_A );
file_put_contents(plugin_dir_path(__FILE__) . 'results.json', json_encode($results));
}
add_action('save_post', 'create_menu');
Then something happened3 that required me to deal with a chunk of issues. I failed to do it in Vue enough times that I got mad and built it again in jQuery.4 You can see Jeff’s pretty code with consts and lets below.
function hasAnyGrandchildren (tree){
let newTree = []
let length = tree.length
for (let i = 0; i < length; i++) {
const node = tree[i]
let hasGrandchildren = false
if (node.children){
let children = this.hasAnyGrandchildren(node.children)
children.forEach(child => {
if (child.children && child.children.length > 0) {
hasGrandchildren = true
}
})
}
node.hasGrandchildren = hasGrandchildren
newTree.push(node)
}
return newTree
}
function createTree () {
fetch( histology_directory.data_directory+'/results.json' ) //histology_directory.data_directory+'/results.json'
.then(result => {
result.json().then(json => {
function parseTree(nodes, parentID){
let tree = []
let length = nodes.length
for (let i = 0; i < length; i++){
let node = nodes[i]
if(node.post_parent == parentID){
let children = parseTree(nodes, node.ID)
if (children.length > 0) {
node.children = children
}
tree.push(node)
}
}
return tree
}
const completeTree = parseTree(json, "0")
const annotatedTree = this.hasAnyGrandchildren(completeTree)
this.tree = annotatedTree
//console.log(annotatedTree)
publishTree(annotatedTree)
return annotatedTree
})
})
}
And then I come in with this mess of stuff. You can see most of it explained in the comments. It added things like arrows for pages that would expand in the menu (rather than taking you to pages), it set the URL so you could link to expanded menu items via a URL, it removed the additional descriptions from overview pages, etc.
//DOING MOST OF THE CONSTRUCTION WORK via concat bc I am lazy
function publishTree(tree){
var menu = ''
tree.forEach(function(item){
//console.log(item)
if ( item.hasGrandchildren === true) {
menu = menu.concat('<li><h2>' + item.post_title) + '</h2>'
menu = menu.concat('<div class="cell-main-index">')
menu = menu.concat(makeLimb(item.children, 'childbearing top'))
menu.concat('</li>')
menu = menu.concat('</div>')
limbMenu = ''
}
})
jQuery(menu).appendTo( "#app ul" );
stunLinks()
checkUrl()
specialAddition()
}
var limbMenu = ''
//OOOOOH RECURSION for limb construction
function makeLimb(data, type){
limbMenu = limbMenu.concat('<ul>')
data.forEach(function(item){
if (item.hasGrandchildren === true){
limbMenu = limbMenu.concat('<li><a id="menu_' + item.ID + '" class="' + type +'" href="' + item.guid + '">' + overviewClean(item.post_title) + ifParent(item.hasGrandchildren) + '</a>')
makeLimb(item.children, "childbearing")
limbMenu = limbMenu.concat('</li>')
} if (item.children && !item.hasGrandchildren) {
limbMenu = limbMenu.concat('<li><a class="live" href="' + item.children[0].guid + '">' + overviewClean(item.post_title) + '</a>')
makeLimb(item.children, "live")
} //this is super ugly but this appears to be the only item that violates the pattern
if (item.post_title == "Overview of connective tissues"){
//console.log(item.post_title + ' foo')
limbMenu = limbMenu.concat('<li><a class="live" href="' + item.guid + '">' + overviewClean(item.post_title) + '</a>')
}
})
limbMenu = limbMenu.concat('</ul>')
return limbMenu
}
//add arrow to indicate menu item has children to display vs taking you to the page URL
function ifParent(kids){
if (kids === true){
return '<i class="fa fa-arrow-right"></i>'
} else {
return ""
}
}
createTree();
//THIS CAME UP BC PAGES WERE CALLED OVERVIEW OF BLAH BLAH BLAH and they wanted to remove the blah blah blah part
function overviewClean(title){
var regex = /overview/i;
var found = title.match(regex)
if (found === null){
return title
} else {
return title.substring(0, 8)
}
}
//MAKE LINKS NOT BEHAVE LIKE LINKS instead add/remove classes
function stunLinks(){
jQuery(".childbearing").click(function (e) {
e.preventDefault();
jQuery('.active').removeClass('active');
jQuery(this).parent().children('ul').toggleClass('active');
jQuery(this).parentsUntil('.cell-main-index').addClass('active');
updateURL(jQuery(this)["0"].id)
});
}
//GET THE URL PATTERN TO EXPOSE MENU LEVELS via parameters
function checkUrl(){
var id = getQueryVariable("menu");
if (id){
jQuery('#'+id).parent().children('ul').addClass('active');
jQuery('#'+id).parents().addClass('active');
}
}
//from https://css-tricks.com/snippets/javascript/get-url-variables/
function getQueryVariable(variable)
{
var query = window.location.search.substring(1);
var vars = query.split("&");
for (var i=0;i<vars.length;i++) {
var pair = vars[i].split("=");
if(pair[0] == variable){return pair[1];}
}
return(false);
}
//THIS WAS DONE BC *ONE* PAGE DIDN'T FIT THE PATTERN
function specialAddition(){
if (document.getElementById('menu_325')){
var exocrine = document.getElementById('menu_325')
var parent = exocrine.parentElement.parentElement
var node = document.createElement('li'); // Create a <li> node
var a = document.createElement('a'); // Create a text node
a.setAttribute('href', 'https://rampages.us/histology/?menu=menu_212');
a.textContent = 'Endocrine ';
node.appendChild(a); // Append the text to <li>
parent.appendChild(node);
a.innerHTML = a.innerHTML + '<i class="fa fa-arrow-right"></i>'
}
}
//make url change per menu change so it's easier to share links etc.
//from https://eureka.ykyuen.info/2015/04/08/javascript-add-query-parameter-to-current-url-without-reload/
function updateURL(id) {
if (history.pushState) {
var newurl = window.location.protocol + "//" + window.location.host + window.location.pathname + '?menu='+id;
window.history.pushState({path:newurl},'',newurl);
}
}
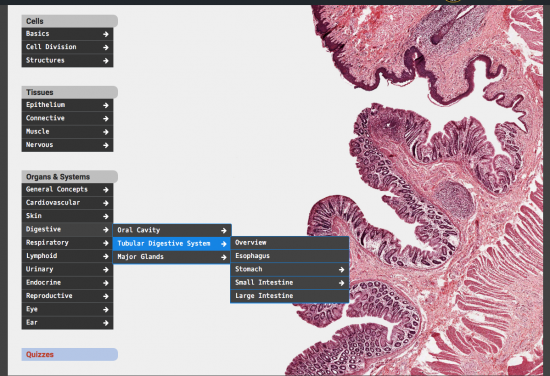
We now have something that’s pretty decent on desktops but I really need to rethink it fundamentally for mobile. One the histology faculty side there is a dislike that bottom tiering menu items like Ear->Inner Ear break the “frame” as they expand downward. In the previous application, I think they just hand assigned how things would layout. That’s relatively easy when you only have one window size and don’t allow people to alter things in a fluid manner. This kind of thing is something that can be dealt with but on my end I have to weigh the effort to do it across a variety of screen sizes vs the impact it’s likely to have on the average user on the site. Right now I can’t justify putting in the extra time.
Recently there was the desire to add multiple background images for the home page. I added an ACF repeater field for images and used a PHP function to randomize between the elements added there.
function randomHomeBackground(){
$rows = get_field('background' ); // get all the rows
$rand_row = $rows[ array_rand( $rows ) ]; // get a random row
$rand_row_image = $rand_row['background_image' ]; // get the sub field value
return $rand_row_image;
}
That gets used in the template like so.
<div id="content" class="clearfix row" style="background-image: url(<?php echo randomHomeBackground() ;?>)">
The Cell Pages
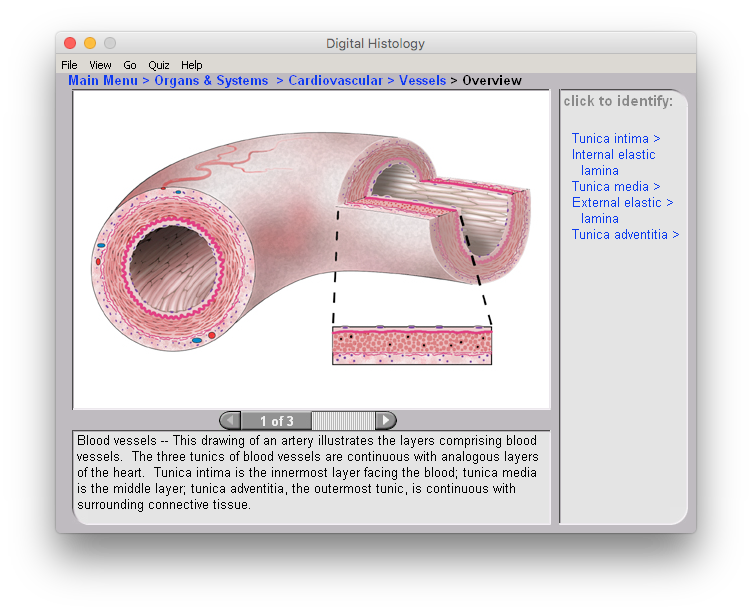
You can see the previous layout above. We have an annotation layer on the right which adds overlays to the existing image and changes the text displayed under the cell. We also have the ability navigate through additional cell images which change the annotation layers but still relate to the main topic.
So each page that is associated with content has a template that’s tied into ACF. It has a repeater field that lets the author associate as many title, description, and image pairings as they’d like and uses them to build the navigation on the right side.
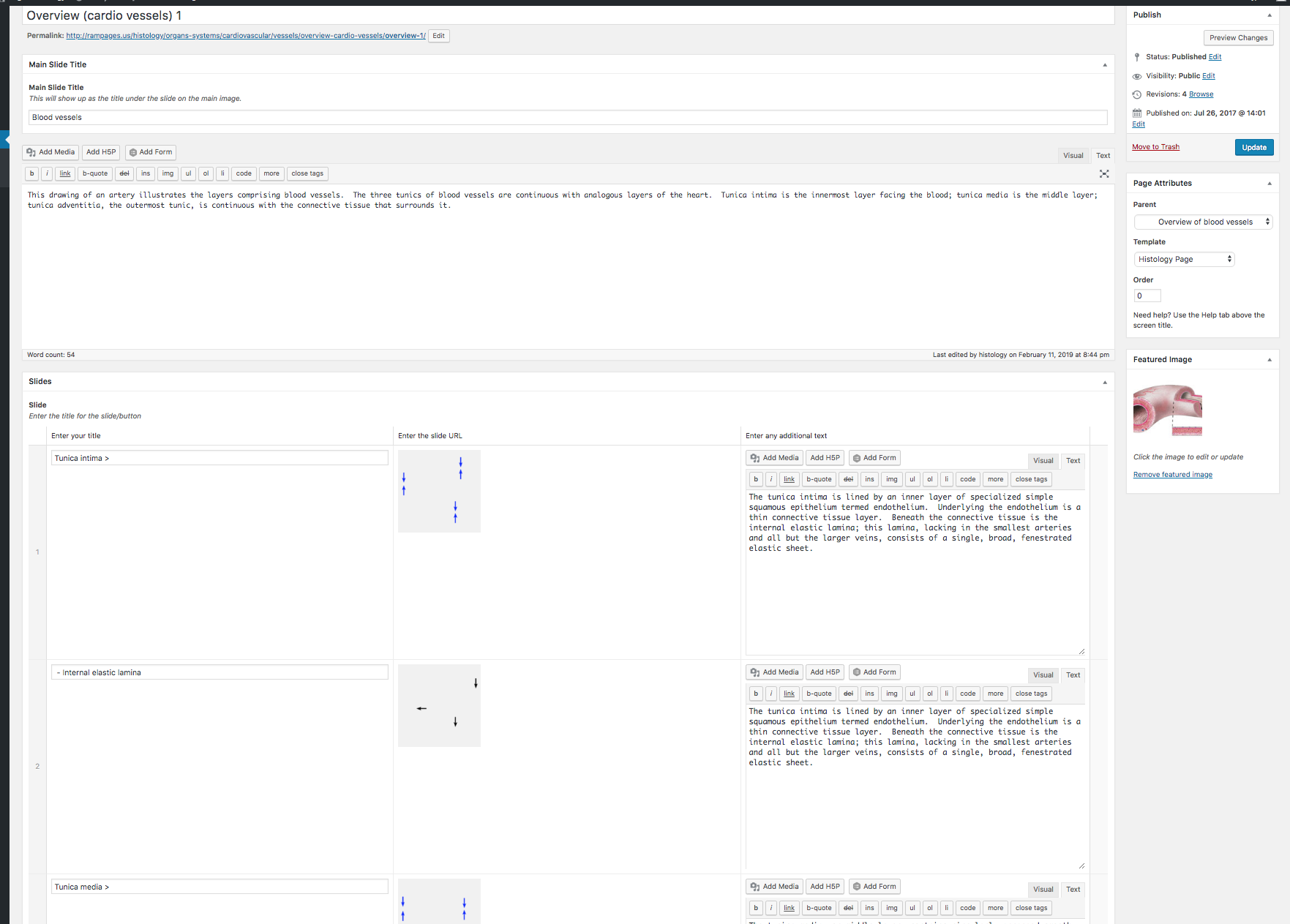
The navigation on the bottom is built by querying other pages with the same parents. You can see a slider element in the old version and there’s been discussion about including a similar slider. I don’t believe it would work well in this scenario for a variety of reasons so I’ve been resistant. In this case we are loading a new page so scrolling would likely be slow and given the wide variation between the number of pages in these structures the layout would be awkward or intensive to develop. I also don’t see scrolling as a common way for navigating this type of web element. It’s not an interaction pattern I see elsewhere and the names don’t give you enough information for informed scrolling. I did tie the arrows to keyboard navigation via some javascript.
//KEY BINDING for nav
function leftArrowPressed() {
var url = document.getElementById('nav-arrow-left').parentElement.href;
window.location.href = url;
}
function rightArrowPressed() {
var url = document.getElementById('nav-arrow-right').parentElement.href;
window.location.href = url;
}
document.onkeydown = function(evt) {
evt = evt || window.event;
switch (evt.keyCode) {
case 37:
leftArrowPressed();
break;
case 39:
rightArrowPressed();
break;
}
};
There’s a bunch of PHP and javascript going on to make all this happen but I wrote most of it around 2 years ago and I don’t want to inflict it on anyone. The nice thing is I’ve learned a lot in two years. The bad thing is considering rewriting the whole thing.5
You might also notice a button labeled ‘hide’ in towards the upper right, it replaces the right hand navigation names with ‘* * *’ and blanks out the text so students can quiz themselves. There’s some other possibilities there that might get more complex but that exists after the latest round of conversations.
//HIDE AND SEEK FOR QUIZ YOURSELF STUFF
function hideSlideTitles(){
var mainSlide = document.getElementById('slide-button-0');
if (mainSlide){
var buttons = document.getElementsByClassName('button');
var subslides = document.getElementsByClassName('sub-deep');
for (var i = 0; i < buttons.length; i++){
var original = buttons[i].innerHTML;
buttons[i].innerHTML = '<span class="hidden">' + original + '</span>* * *';
}
for (var i = 0; i < subslides.length; i++){
subslides[i].classList.add('nope')
}
document.getElementById('the_slide_title').classList.add('nope')
document.getElementById('the_slide_content').classList.add('nope')
document.getElementById('quizzer').dataset.quizstate = 'hidden'
document.getElementById('quizzer').innerHTML = 'Show'
}
}
function showSlideTitles(){
var mainSlide = document.getElementById('slide-button-0');
if (mainSlide){
var buttons = document.getElementsByClassName('button');
for (var i =0; i < buttons.length; i++){
var hidden = buttons[i].firstChild.innerHTML;
buttons[i].innerHTML = hidden;
}
document.getElementById('the_slide_title').classList.remove('nope')
document.getElementById('the_slide_content').classList.remove('nope')
document.getElementById('quizzer').dataset.quizstate = 'visible'
document.getElementById('quizzer').innerHTML = 'Hide'
var subslides = document.getElementsByClassName('sub-deep');
for (var i = 0; i < subslides.length; i++){
subslides[i].classList.remove('nope')
}
}
}
function setQuizState(){
var state = document.getElementById('quizzer').dataset.quizstate
if (state === 'hidden'){
showSlideTitles()
} else {
hideSlideTitles()
}
}
function retainQuizState(){
var state = document.getElementById('quizzer').dataset.quizstate
if (state === 'hidden'){
hideSlideTitles()
} else if (state === 'visible'){
showSlideTitles()
}
}
jQuery( document ).ready(function() {
document.getElementById('quizzer').addEventListener("click", setQuizState);
});
Quizzes
The site also has a set of quizzes built in H5P. They’re on this page based on having the common page parent Quiz. We had to set up some custom CSS to make the images go to full size by default and then add it via some PHP so it’d work the way that we desired.
.h5p-column-content.h5p-image > img, .h5p-question-image-scalable {
width: 100% !important;
height: auto !important;
max-width: 100% !important;
}
.h5p-question-scorebar-container {
display: none !important;
}
function h5p_full_img_alter_styles(&$styles, $libraries, $embed_type) {
$styles[] = (object) array(
// Path must be relative to wp-content/uploads/h5p or absolute.
'path' => get_stylesheet_directory_uri() . '/custom-h5p.css',
'version' => '?ver=0.1' // Cache buster
);
}
add_action('h5p_alter_library_styles', 'h5p_full_img_alter_styles', 10, 3);
1 Watch the pages scroll by . . .
2 I’m not sure if that’s because of the way the project got started or a result of choices I made.
3 I can’t recall what. Thus the need to write these blog posts more often.
4 I am not the cutting edge. I am not the edge. I am not the cut. I am bailing wire, duct tape, and stubbornness.
5 Refactoring if you’re nasty.
Boy Howdy this is the heavy-lifting, god’s work of keeping people’s stuff up-to-date and running. Cannot tell you the stuff that got abandoned, sacrificed in HyperCard, ToolBook, Authorware an Director. That was the golden age of Desktop Multimedia. And you forward migrated it! Congratulations.