

We’ve had a few people who became big fans of populr.me. They’re also using Google Docs/Drive and since I like things to blend . . . here’s how you embed a Google Drive folder into populr.me. The example is here if you want to check it out.

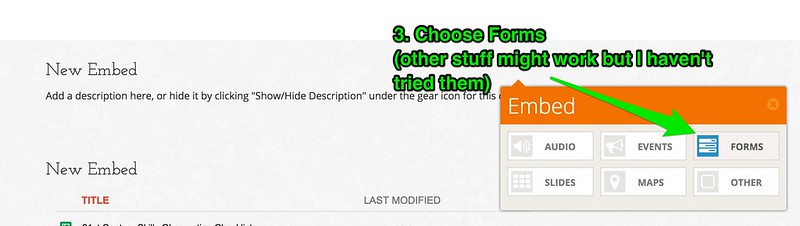
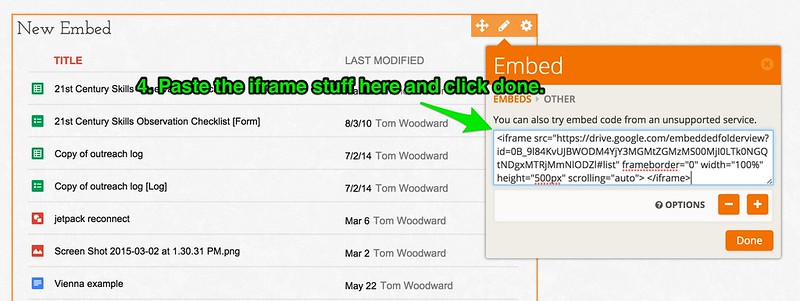
Getting That iFrame Stuff
I started to write directions on how to do this but just built a little tool instead.