
I remain kind of amazed with how many little tricks can be done with Google Sheets. After seeing Alan’s post today, I wonder how much of the data I could pull (assuming we had the right user names and knew the services . . . really the harder part) just using Google Sheets. Turns out we could get a pretty good amount. The following is a mix of XPath, regex, and APIs. I started with as little real programming as possible and gradually increased sophistication.
The following are just meant to get a rough idea of how much stuff you’ve got in the various spaces.
Flickr
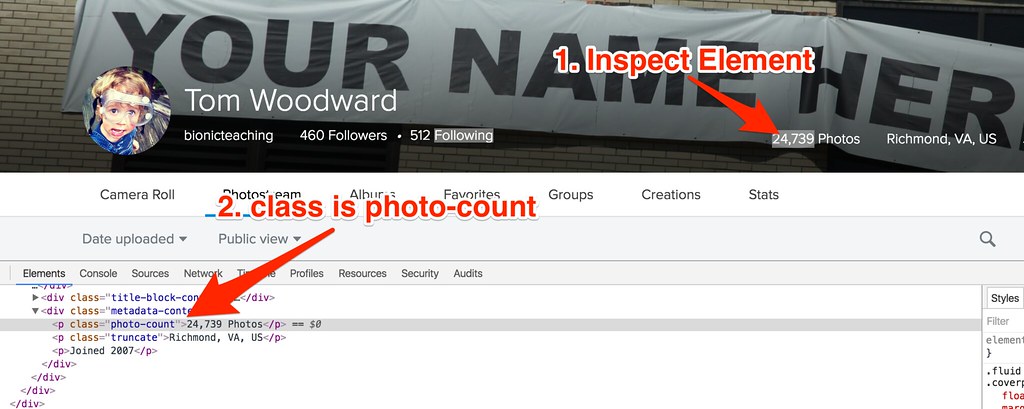
The URL: http://flickr.com/photos/bionicteaching
The function: =IMPORTXML(C2,”//*[@class=’photo-count’]”)
This uses a basic Google Sheets function to grab the photo-count content. The function is grabbing the div class with the title photo-count.
Vimeo
The URL: http://vimeo.com/twwoodward
The function: =INDEX(IMPORTXML(C3,”//*[@class=’stat_list_count’]”),1)
Pretty similar to the example above but with the addition of INDEX. That solves the problem that there are multiple items that are all in the stat_list_count class and we only want the first matching item.
Sound Cloud
The URL: http://soundcloud.com/cogdog
The function: =REGEXEXTRACT(IMPORTXML(C4,”//*[@name=’description’]/@content”),”([0-9]+) Tracks”)
This gets a bit fancier. IMPORTXML brings in a large chunk of content from the page but it wasn’t structured in a way that I could get the exact information I wanted. REGEX comes to the rescue and grabs the chunk that has a pattern of numbers [0-9]+ followed by the word Tracks.
The URL: I cheated and used PHP to grab the data and just hand it off.
The function: =IMPORTXML(“http://bionicteaching.com/tools/reclaim/reclaim_insta.php?user=”&B5,”//*[@class=’reclaim’]”)
$raw = file_get_contents('https://www.instagram.com/' . $user); //replace with user
preg_match('/\"media\"\:\{\"count\"\:([0-9]+)/', $raw, $m);
echo '<div class="reclaim">' . intval($m[1]). '</div>';
YouTube
This is a custom function in Google Sheets. You’d write =myYT(“bionicteaching”) and it’ll return the number of videos.
function myYT(input) {
var ss = SpreadsheetApp.getActiveSpreadsheet();
var sheets = ss.getSheets();
var user = input; //gets the variable from the function
var sheet = ss.getSheetByName("data");
var apiKey = 'THEAPIKEY';// replace this with your API client ID
var url = 'https://www.googleapis.com/youtube/v3/channels?part=statistics&forUsername=' + user + '&key=' + apiKey;
var response = UrlFetchApp.fetch(url); // get feed
var json = response.getContentText(); //
var data = JSON.parse(json);
var stats = [];
stats.push(data.items[0].statistics.videoCount);
return stats; //returns the data to the spreadsheet cell
}
Tumblr
Pretty much the same thing- grab the JSON, parse it, and return it.
function myTumblr(input) {
var ss = SpreadsheetApp.getActiveSpreadsheet();
var sheets = ss.getSheets();
var site = input; // make sure it doesn't have http leading
var sheet = ss.getSheetByName("data");
var apiKey = 'THEAPIKEY';
var url = 'https://api.tumblr.com/v2/blog/' + site + '/info?api_key=' + apiKey; // replace this with your API client ID
var response = UrlFetchApp.fetch(url); // get feed
var json = response.getContentText(); //
var data = JSON.parse(json);
var stats = [];
stats.push(data.response.blog.total_posts);
return stats;
}
Now we’re talking, or scraping. I am wary of the scrape / Xpath route; like my first generation Flickr CC Attributor, everything breaks when Yahoo (or whomever becomes their next overlord) alters the display of flickr content. The API way is the way, writing something to get info from flickr is not hard.
The tripping point is authentication. Getting those keys is a PITA. Wonder about doing some authorization stuff the way Martin Hawksey does the twitter auth in his TAGs sheets.
Oh, what I meant to say is “thanks” for doing this.
I think I like xpath because it’s more of a puzzle and reminds me of non-programistan. 🙂 I was also thinking of avoiding people having to get an API Key just to this exploratory stuff. I figured that’d be a roadblock. Thinking about it more though, I think I’ll just use my keys for the service side
Two of them are official API returns though, I’ll probably do the others that way this evening.
Hi Tom,
Thanks, This looks like a nice rabbit hole.
Went to give this a quick try this morning and on my flickr page (and yours) I don’t see the photo count. Wondering if temporary or another change?
Screenshot:
https://www.flickr.com/photos/troutcolor/26379416160
the paragraph is still there so the formula works, but I needed to straighten the quotes
Thanks Again
I played around with that a bit and I think it’s a responsive feature. On a big screen it shows. I think I’m going to re-do the flickr one to use the API anyway.
Hi Tom
you are right, I can see on my work box or if I hit cmd minus on the laptop. Thanks again.
Heyy,
I also want to do a smiliar thing with the ‘followed by’ count of Instagram, can you please help me out?
And when I run your Instagram code it shows that https wrapper is unavailable.
Yep. Cogdog’s dire warnings of changes impacting the scraping occurred when Instagram added that hideous icon. I fixed it and added followers/following to the mix. Still better than Instagram’s new stupid API restrictions 🙂
For instagram, could I grab users & its followers? Plus is it also possible to scrap users from a particular location e.g. California (without knowing all the users)? Any help? Thanks.
You could get follower count (you can see that here) but I don’t think the latter is possible.
Hello Tom, thanks for your article. I’m not very familiar with programming but google spreadsheet is opening some doors to my curiosity.
I’d like to ask if (‘/\”media\”\:\{\”count\”\:([0-9]+)/’, $raw, $m ) in your Instagram section could be used as REGEX argument in a formula like =REGEXREPLACE(CONCATENATE(IMPORTDATA( instagram url ));”(^.*media: {“”count””: )(\d+)(}.*)”;”$2″) – that is similar to a followers count scrape I’ve found while googling.
I spent a long time doing semi-programming in spreadsheets. It’s a friendly place that I highly recommend.
You’re correct, that’s a regex argument. As mine is in PHP it’s slightly different than what javascript will let you do and Google has other restrictions if I recall correctly.
Assuming you’ve got the Instagram URL you want in cell A1, then this ought to work to return the numbers of users that person follows.
=REGEXEXTRACT(concatenate(IMPORTDATA(A1)),”follows: {.count.: [0-9]+”)
This would return the number of followers they have
=REGEXEXTRACT(concatenate(IMPORTDATA(A1)),”followed_by: {.count.: [0-9]+”)
Actually this one ends up being much cleaner
=REGEXEXTRACT(concatenate(IMPORTDATA(A1)),”(?:followed_by: {.count.: )([0-9]+)”)
I tried using both the php script and this formula to display followers but neither one worked. Is this still working or am I missing something?
Assuming the Instagram URL is in cell A1, give this a shot . . .
=REGEXEXTRACT(concatenate(IMPORTDATA(A1)),”(?:followed_by: {.count.: )([0-9]+)”)
I did some different PHP stuff more recently. You can see that here.
This works for Instagram followers, follows and posts:
This works after the API change. I added ” col-md-4″ to the original instructions.
Copy exactly what I have below into your google spreedsheet. A3 refers to the Instragram user in name without @ or URL.
=IMPORTXML(“http://bionicteaching.com/tools/reclaim/reclaim_insta.php?user=”&A3,”//*[@class=’followers col-md-4′]”)
=IMPORTXML(“http://bionicteaching.com/tools/reclaim/reclaim_insta.php?user=”&A3,”//*[@class=’follows col-md-4′]”)
=IMPORTXML(“http://bionicteaching.com/tools/reclaim/reclaim_insta.php?user=”&A3,”//*[@class=’reclaim col-md-4′]”)
-Taz
Just wanted to say thanks for the instagram one. I tweaked it a bit and made it work to get the follower count:
=IMPORTXML(“http://bionicteaching.com/tools/reclaim/reclaim_insta.php?user=”&A1,”//*[@id=’followers’]”)
Thank you so much! 🙂
Nice! Appreciate you following up.
Hey thanks for the post. just wondering reffering to the Instagram.
1.can I use google sheets to grab my followers name?
2.where did you putt the php code? what was the process
thanks in advance,