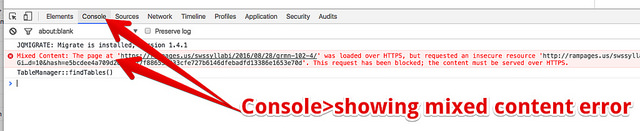
I still use Sublime when I’m not using VS Code. This isn’t the best idea but I do it anyway. One of the things I like about both programs is being able to create little shortcuts to create code I write a lot. It speeds things up and makes me more consistent. Both programs let […]
Read More… from Multiple Regex Expressions in a Sublime Snippet