

flickr photo shared by Internet Archive Book Images with no copyright restriction (Flickr Commons)
A week or two ago some faculty members asked me about getting the Leadership Education in Neurodevelopmental Disabilities (LEND) content out of the Moodle hosted at Vanderbilt and into WordPress. I figured I could do this. Someone might even have done it already. If not, I figured the export options would have to put out something fairly straightforward that could be parsed. In any case, the majority of my learning comes from committing to things I don’t quite know how to do.
Turns out I couldn’t find anyone who’d done this before. I went a variety of different routes as I attempted not to do the work myself. First, I exported the course in the two different flavors that were available (SCORM1/Course Cartridge and Moodle backup). Just for fun I tried a few different flavors of import plugins . . . Edwiser Bridge might have worked but required a higher level of connection to Moodle than I felt like dealing with and seemed more focused on integration rather than migration, Simple CSV Importer and WP All Import both failed to do what I needed despite pushing XML around a bit to try to make it work. So with all the ready-made solutions exhausted2 I turned to the export files. As I wandered, I found a way to extract files from the Moodle backup using Python. That would likely be useful but wasn’t quite what I needed.
A Dead End
3
I then looked at the SCORM export (to see the innards change the extension to zip and unpack it). The central indexing file there is imsmanifest.xml. It is not something I found to be very intuitive. It’s one giant XML file, a portion of which is below. It’s a big list in this case- 4300+ lines of data. Basically, the identifierref elements reference resource identifierref elements that then reference folders and/or files. It took me a while to figure this out (aka – I asked on Stack Overflow) as the initial item identifier pieces don’t seem to link to anything else. For instance, I_89A00510 is found only once in the xml file. I thought it’d be the key to associate that item with the content for that page but I never quite figured that out. I was able to import all the sub-pages4 in as content but it didn’t have parent/child relationships and the component pieces were often called the same thing. After doing all this, I realized part of my problem was that I didn’t know or understand the initial Moodle structure well enough to know when I was missing key elements. Stupid, I know but sometimes I must learn through pain.
<organizations>
<organization identifier="O_8DA0CAEE" structure="rooted-hierarchy">
<item identifier="root">
<item identifier="I_88671EB7">
<title>0</title>
</item>
<item identifier="I_9AB82CBF">
<title>Moodle Help Center</title>
<item identifier="I_0089CDA6">
<title>A. &nbsp;Videos on the Moodle Basics
Kojo Nyame h...</title>
</item>
</item>
<item identifier="I_89A00510">
<title>Applying Research to Inform Evidence Based Practice: Focus on Autism Spectrum Disorders</title>
<item identifier="I_3D430750">
<title>Module Description
This module will assist the le...</title>
</item>
<item identifier="I_AECCCABB" identifierref="I_219D9605_R">
<title>I. Preparation</title>
</item>
<item identifier="I_B0C5A138" identifierref="I_6B507EBE_R">
<title>II. Additional Resources</title>
</item>
<item identifier="I_41E6A015" identifierref="I_6A4D7306_R">
<title>III. Assignments</title>
</item>
</item>
<item identifier="I_F6CACDDD">
<title>Autism: Adolescent and Early Adult Years</title>
<item identifier="I_AB91D468">
<title>Module Description
In this module, trainees will ...</title>
</item>
<item identifier="I_79C977EC" identifierref="I_0F8C1900_R">
<title>I. Preparation</title>
</item>
<resource identifier="I_5C671C7E_R" type="webcontent" href="i_10cd491e/ii.__additional_resources.html">
<file href="i_10cd491e/ii.__additional_resources.html"/>
<file href="i_9567c606/travers_2014_racial_disparity.pdf"/>
<file href="i_9567c606/goin-kochel_2006_how_many_doctors.pdf"/>
<file href="i_9567c606/bradshaw_2014_feasibility_and_effectiveness.pdf"/>
<file href="i_9567c606/vivanti_2014_effectiveness_and_feasibility.pdf"/>
<file href="i_9567c606/estes_2014_impact_of_parent-delivered.pdf"/>
<file href="i_9567c606/warren_2011_systematic_review.pdf"/>
<dependency identifierref="I_6EE69C9D_R"/>
<dependency identifierref="I_A0A3F23D_R"/>
<dependency identifierref="I_56F15652_R"/>
<dependency identifierref="I_9E129E4F_R"/>
<dependency identifierref="I_BBDA8CE4_R"/>
<dependency identifierref="I_35ED01AB_R"/>
<dependency identifierref="I_E323717E_R"/>
</resource>
A Solution
After spending some time figuring out the structure of the course in Moodle I decided I needed a break from the SCORM piece as it was making me angry so I switched to the Moodle export option.
I got the guts of the Moodle export by changing the extension from mbz to zip and extracting as normal. That gave me a very different file structure. With this export there were a few xml files at the root of the directory and a few different folders. The relevant pieces ended up being moodle_backup.xml and the activities and sections directories.
<activity>
<moduleid>6</moduleid>
<sectionid>4</sectionid>
<modulename>label</modulename>
<title>Module Description
In this module, trainees will ...</title>
<directory>activities/label_6</directory>
</activity>
<activity>
<moduleid>7</moduleid>
<sectionid>4</sectionid>
<modulename>page</modulename>
<title>I. Preparation</title>
<directory>activities/page_7</directory>
</activity>
<activity>
<moduleid>8</moduleid>
<sectionid>4</sectionid>
<modulename>page</modulename>
<title>II. Additional Resources</title>
<directory>activities/page_8</directory>
</activity>
It took me a bit to parse out the various pieces but eventually I figured out how the various pieces fit together. It’s something like the image below and it knits various xml files together from various directories.
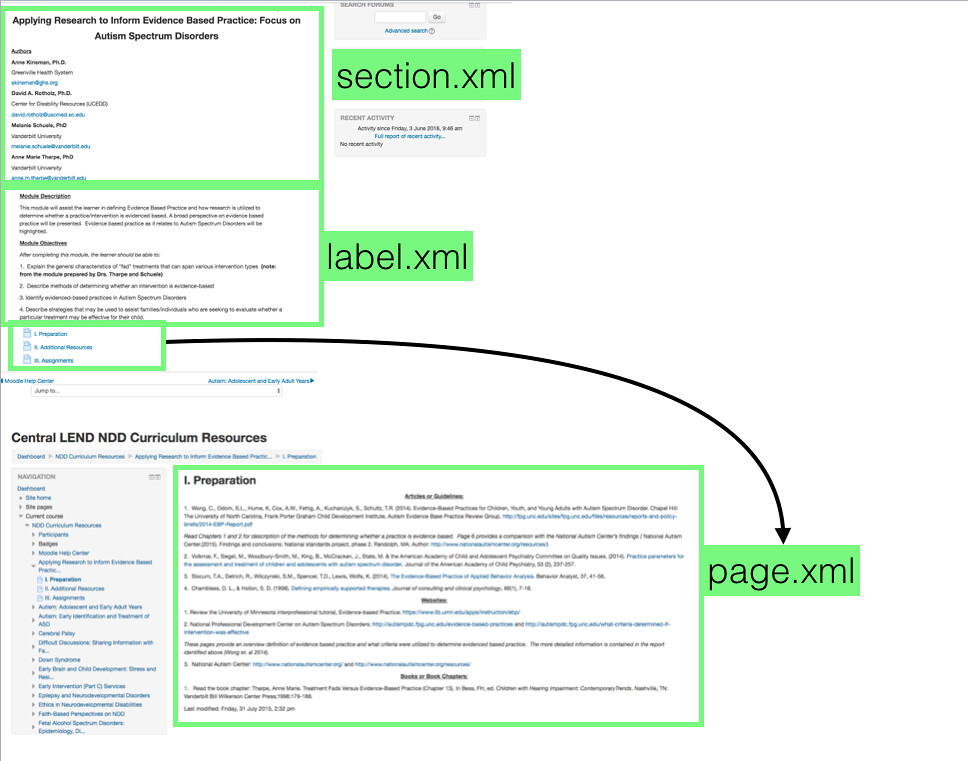
Here’s a plugin that seems to work pretty well based on my tests. It pulled in 200 or so pages and kept the parent/child relationships. I added a little shortcode piece from the page-list plugin,5 that puts links to the child elements at the bottom of each parent page.
The plugin is activated by going to http://rootURL.com/?run_my_script and the moodle backup file is hardcoded (see below). Not beautiful but functional enough for me at the moment. You’ll also see lots of var_dump or echo statements commented out. I left them in there in part to help show how I figure out if something is working. Prior to adding the WP plugin code, I just see if I can parse out the elements into a page. If I can do that then it’s just a matter of sorting them into the slots that WP provides. I learned how to do that when playing with Adam’s discography import. I mention that because I find this kind of learning always has positive echoes.
<?php
/**
* Plugin Name: IMPORT MOODLE
* Plugin URI: https://github.com/woodwardtw/
* Description: Parses moodle_backup.xml to create WP pages
* Version: 1.1
* Author: Tom Woodward
* Author URI: http://bionicteaching.com
* License: GPL2
*/
/* 2016 Tom (email : bionicteaching@gmail.com)
This program is free software; you can redistribute it and/or modify
it under the terms of the GNU General Public License, version 2, as
published by the Free Software Foundation.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program; if not, write to the Free Software
Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA
*/
if ( isset($_GET['run_my_script']) ) {
add_action('init', 'makePages', 10);
add_action('init', 'script_finished', 20);
}
function script_finished() {
add_option('my_script_complete', 1);
die("Script finished.");
}
function makePages(){
$file = 'http://192.168.33.10/mood2/unzip/moodle_backup.xml'; //load the main backup file ****hardcoded so point it at your file
if (($response_xml_data = file_get_contents($file)) === false) {
echo "Error fetching XML\n";
} else {
libxml_use_internal_errors(true);
$data = simplexml_load_string($response_xml_data);
if (!$data) {
echo "Error loading XML\n";
foreach (libxml_get_errors() as $error) {
echo "\t", $error->message;
}
} else {
$activityCounter = count($data->information->contents->activities->activity); //how many things do we have
echo 'total count ' . $activityCounter . '<br>';
for ($x = 0; $x < $activityCounter; $x++) {
$moduleid = $data->information->contents->activities[0]->activity[$x]->moduleid[0];
$sectionid = $data->information->contents->activities[0]->activity[$x]->sectionid[0];
$directory = $data->information->contents->activities[0]->activity[$x]->directory[0];
$underscore = strpos($directory, '_'); //should probably replace this with some regex ....
$slash = strpos($directory, '/');
$xmlPage = substr($directory, $slash, ($underscore - $slash));
//echo 'xmlPage ' . $xmlPage . ' <br/> ';
//echo 'the underscore is ' . $underscore . ' <br/> ';
//echo 'the slash is ' . $slash . ' <br/> ';
// echo 'the module is ' . $moduleid[0] . ' sectid - ' .$secionid[0] . ' directory - ' . $directory .'<br/>';
$directoryContent = 'http://192.168.33.10/mood2/unzip/' . $directory . $xmlPage . '.xml'; //*****hardcoded ******* point appropriately
$sectionContent = 'http://192.168.33.10/mood2/unzip/sections/section_' . $sectionid . '/section.xml'; //******hardcoded ******* point appropriately
//echo $directoryContent;
$theContent = simplexml_load_file($directoryContent); //load up the xml file per subfolder to main pages if that thing is a label (as opposed to a page) it makes it a parent page
if ($xmlPage === '/label') {
$theSectionContent = simplexml_load_file($sectionContent);
$pageTitle = $theSectionContent->name;
$pageSummary = $theSectionContent->summary;
$labelName = $theContent->label->name;
$labelIntro = $theContent->label->intro;
$content = $pageSummary . '<br/>' . $labelName . '<br/>' . $labelIntro . '<br/>[subpages]'; //the content for the parent page with the shortcode to list child pages
$my_post = array(
'post_title' => $pageTitle,
'post_content' => $content,
'post_status' => 'publish',
'post_author' => 1,
'post_type' => 'page',
);
$the_post_id = wp_insert_post( $my_post );
$page = get_page_by_title( $pageTitle);
$parentId = $page->ID;
} else {
$childTitle = $theContent->page->name; //child page creation
$childContent = $theContent->page->content;
$my_post = array(
'post_title' => $childTitle,
'post_content' => $childContent,
'post_status' => 'publish',
'post_author' => 1,
'post_type' => 'page',
'post_parent' => $parentId, //assigns the parent ID
);
$the_post_id = wp_insert_post( $my_post );
}
}
}
}
}
1 I’m pretty sure this is a comic book villain.
2 Exhaustion being defined as the limits of my own patience divided by skill at Googling times a masochistic interest in building it myself . . .
3 Educational and all that but mainly just documenting a failure.
4 Included as an example of what not to do.
2 thoughts on “Importing Moodle into WordPress”
Comments are closed.