Back in April, I did the first version of this presentation. That’s roughly 4 months ago. It feels like a lot has changed since then. As I revisited the presentation, I changed quite a bit. Some of those changes were due to the technology changing. Some changed based on my experience. I listened to 7 or 8 or 100 hours of the Latent Space AI engineer podcast while driving back from Vermont. A good chunk was over my head but it was interesting to hear a really different perspective on things. Some of the changes were just to get people doing something earlier. Zoom presentations always feel especially disconnected to me. It can also be a lot to juggle as I try to copy things into the chat, read the chat, and mix the slides with live examples. I was lucky to have Amy helping out in this workshop. I did end up with about 1 hour more of content than I had time for. Below you can find some of the changes that seemed worth calling out. The whole presentation is here.

Setting the stage
I want to really emphasize that AI or even LLM is a really vague term. I thought the word car was a decent parallel. AI is a big term like the word car . . . and you might want different cars for different reasons, speed, cost, miles per gallon, goals (win a race, carry people, etc). The same is true for AI and with equally different options for different goals. You might also end up preferring one to another based on things that are harder to define. Maybe it just works better based on how you use it. Banning all aspects of AI is going to be difficult. Especially as the LLMs become more deeply integrated into so many tools. Expect a whole lot of gray in the black/white world of to AI or not to AI.
The space is expanding rapidly in both capability and total number of models. I show a screenshot of Hugging Face that I took in April. It had 561,000 models. I took another at some point and it had risen to 719,000 and the one I took on Aug. 23 was 861,342 models. That’s a pretty dramatic increase and it’s likely to keep moving.
We are going to focus on general intelligence LLMs today. Those are the Swiss Army knife of LLMs. Many can take multimodal inputs these days (text, images, audio) and create multimodal outputs. They’re meant to do a wide array of things decently and to do them without requiring additional fine tuning or training.

Prompting is shaped by the model you’re interacting with. The image above shows a few of the more popular models right now and the corporations associated with them. You’ll want to try out various models and find the ones that work best for you in various scenarios. Claude appears better at SQL programming than ChatGPT. I thought Gemini did better for Google Scripts programming. That makes sense given Google is responsible for Gemini. It is a strange place. Copilot runs on top of ChatGPT but I find the results to be different enough to be noticeable. The images I get from Copilot align better to my prompts then what I get from GPT. At the same time, I like the text interactions with ChatGPT better than with the Bing Chat/Copilot. All that just to say, the field is messy. Like choosing between Coke and Pepsi . . . you might just like a particular LLM better. Try a few. Figure out what works for you.
So the goal here is to bounce around a bit between LLMs and to show you what’s possible, techniquest to help get it, and things to look out for.
Prompting basics
- Be clear
- Be specific
- Use complete sentences
- Use proper grammar
- Use punctuation correctly
- Politeness may influence results*
- Don’t be afraid to correct or refine
I put these tips earlier than previously and I did a bit more explaining that it’s not like the LLM cares if you are polite or grammatically correct . . . it’s just helping get the math from your prompt to the kind of answers you want . . . and higher quality answers tend to be associated with better grammar and politeness.1 You could probably use 1337 speak and end up with better dark web hacker responses. As people who work at a liberal arts institution we can appreciate a tool where having a good vocabulary and a creative mind for communication can lead to better results.
A prompt progression
So now, I’m going to be running these prompts live in various LLMs while the workshop participants do the same. We’ll toss interesting things in the sidebar etc.
This prompt is chosen because it’s pretty factual. All my tests got a good answer. Most responses provided additional information you might not have thought off (like atmospheric pressure). It’s what people expect in this scenario.
This still seems to almost universally fail. The response is almost always 2 and it is somewhat difficult to get it to give you the right answer (3). I like the juxtaposition here and it helps reinforce that the LLM doesn’t know right from wrong.
This works well for me in ChatGPT 4o but Gemini still struggles. But you can see how vocabulary and knowledge in different domains might help you get what you want AND that when you ask questions about things you don’t know about . . . answers may be incorrect. If it’s still wrong for you, try telling it that and asking it to try again. That is a technique that’s part of this kind of conversational programming. This prompt is also an example of procedural (first, then, etc) which is something that helps AI responses.
This lets us compare some responses. See which LLMs are tied into live Internet vs just archived data. It also exposes some USA-centric biases and then lets us correct the LLM and refine our prompts to get what we want.
Data manipulation
Manipulation is a loaded term with AIs. What I mean here is just the ability to shift content around in various ways. It’s something I don’t see a ton but find useful.
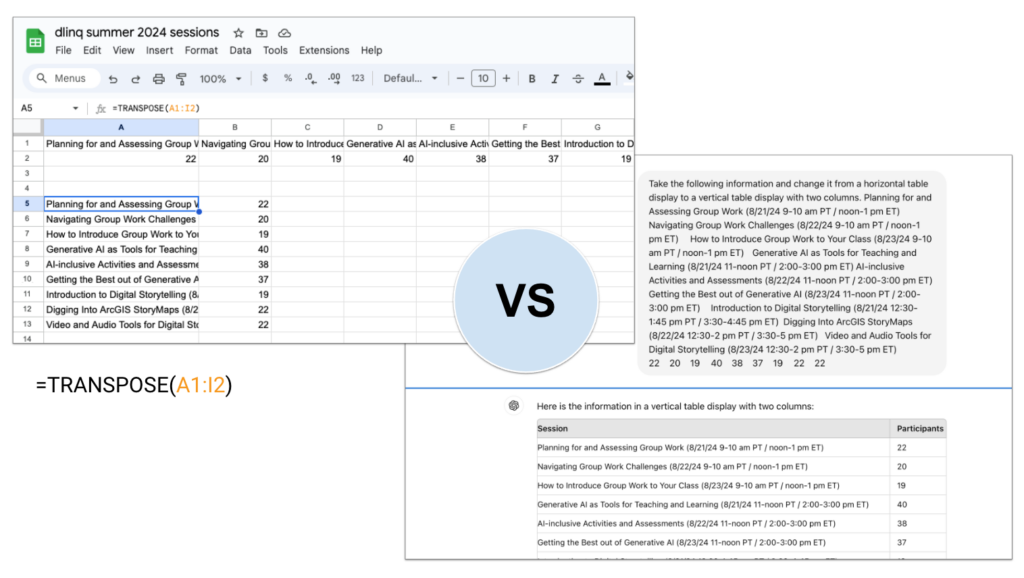
Here you can see me flipping some attendance data for this workshop series from a horizontal array into a vertical array. In the first screenshot, I know to use the TRANSPOSE function. In the second, I just ask ChatGPT and paste in the data. Both work. Does the AI path matter? It does if I’m trying to teach Sheets/Excel functions. It might also matter if that data was confidential depending on which service I was using. If neither of those things is true, then I can’t see why it would matter.

ChatGPT and Gemini did a pretty decent job transcribing both of these images. The handwritten notes were meant to be as messy as possible while still being legible to me. The OCR aspect of LLMs is something I haven’t seen used a ton. This seems really handy if you’re already using the tool for other things.
Creative content generation
From here I went back to playing around with poems and various parameters. I think they’re nice because you can get specific and see if the LLM obeys you. You have the opportunity to correct it and the product is limited in length and generally amusing. You can see 4 line fish poems by Suess, Moore, and Hugo here. The syllable counting has improved markedly from 4 months ago. Participants were encouraged to try to stump the AI. I could do that previously by asking for an ABC/ABC rhyme scheme. That’s no longer the case in most models.
1 As you sow, so shall you reap?
I told you that I’ve been re-using an earlier version of this workshop (though I am starting to incorporate a few other bits, so the theft is slightly less egregious lately). I find it a useful starting point that I can get people working off of and playing with, while we usually end up talking about the many issues that AI raises with people. I find myself enjoying the sessions, and people seem to find them worth the time. So please accept my thanks for this update. I also appreciate the context you are offering here.
And thank you for the pointer to Latent Space. I can’t imagine how far over my head it will be.
You cannot steal what is freely given. I’m pretty sure that Yoda said that. If not, I said that. Or maybe it was a Brooklyn 99 line.
I’m always glad to hear someone else is getting some benefit from this. We do so many similar things. It’s insane to start from scratch each time.
The Latent Space podcast certainly has chunks that I have no clue on. I do find the majority of it to be interesting though, in part because it’s totally not from an edu view. The guy running the chatbots for onlyfans was a crazy interview. Such a business focus on extracting money. Crazy.