Image from page 93 of “Elementary and dental radiography” (1813) flickr photo by Internet Archive Book Images shared with no copyright restriction (Flickr Commons)
This is the blow-by-blow documentation of a failure of sorts. Nothing makes me angrier than failing to deliver on something I said I could/would do. I ended up delivering what was needed but the way I had to do it was ugly and time-intensive. All of this happened because of two things- insufficient initial testing and not enough knowledge on my end at a couple of key steps. I’ve got lots of ideas I need to test out now that I’ve learned a few things the hard way but I thought it’d be beneficial to see how I tried to think through this thing when various paths failed . . . and with that welcome to my postmortem.
I thought we had the Social Work Google Docs Digital Portfolio thing figured out. I even wrote a blog post. Events coalesced to remind me that I do not know enough stuff. However, I do intend to learn from painful mistakes like this and give you my tears and frustration for you free of charge.1
Initial tests felt a bit slow but nothing too bad. Google Scripts will timeout after 6 minutes but I thought we’d be ok based on tests I ran with my mock-folder structure. We did some additional tests and things seemed good. Folders were created and shared. A good time was had by all.
Because of the way the world works, the script was run for real on the ~100 students at around 3:40 PM2 the day before it was going to be put into action. Things seemed good for student 1, student 2, student 3 . . . student 4 . . . and it timed out at student 5.4. Not good.

6 minutes of processing to get 4 clean copies didn’t play out nicely- 150 minutes to do all of them (not including removing the partial copies) . . . assuming we didn’t cap out our total processing time for the day. Crap. The gentleman on the hook for this all working for the next day was concerned but polite and kind. I told him I’d keep him updated.
At this point I had around 20 correctly copied folders and time was marching on. 80 to go. I modified the script so it just created the top-level folder and assigned the correct sharing permissions. This only took a few minutes to generate the remaining 80 folders and write the correct data to the spreadsheet but I still needed to fill them.
In what I thought was a clever move, I downloaded the folder structure from Google Drive, unzipped it on my desktop and drag/dropped to the student folder. Ugly. Very ugly but it looked good. My normal technique would have been to open the student folders in a ton of tabs and drag/drop and close the tab after the upload completed but because Google Drive is Google Drive opening folders in tabs is not as pleasant an experience as it is on a normal website. With time passing, I just navigated within the Google drive and got to drag/dropping. I’d have to pause occasionally to let things catch up or the browser would crash.
80 folders later I was displeased but done is done. I opted to take a few verification looks . . . and realized that on download the native Google Docs had transformed to docx and on upload . . . had remained docx. I said a number of words at that point indicating my dissatisfaction with myself and the world in general.
The mechanical answer at this point was to go to the document (1) in the subfolder (31) for all the students (100)
sucky, sucky misery

I did a chunk of searching and I believed I found a way to transform MIME types via Google Script but it required the Drive Advanced API to be activated. That’s blocked on our VCU accounts.3

I tried to be clever and I synced the folder to my Google Drive App and then copy/dragged that content to the desktop. That kept the gdoc extension etc. Hope soared. I uploaded them but for a reason I entirely don’t understand Google Drive couldn’t figure out how to open files in their own format. So failure music played and I cursed a bit more. So much for being clever.
After more thinking/Googling/cursing, I took a look at the Settings for Google Drive and checked a box.
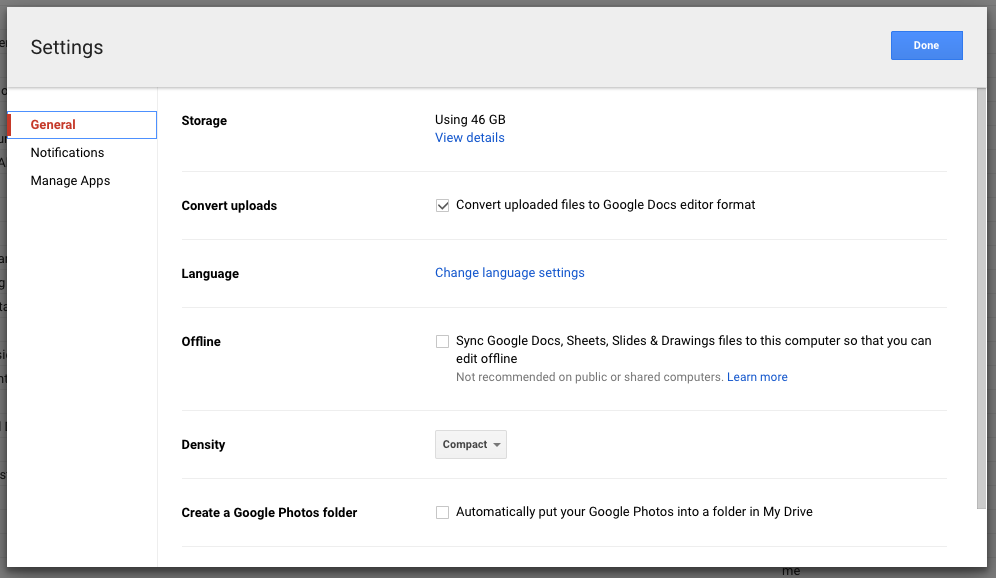
That setup automatic conversion of docx to Google Doc format. It would have been nice to have thought to do that on the first round of hand-uploads.5
So new pattern. Open student folder. Delete all. Drag/drop folder structure. Repeat until 40 or so files were in process and then wait for the queue to process. This only seemed to work in Chrome Canary but my ability/willingness to really figure out the issue at this point was limited. Overloading the queue lead to browser crashes so patience was the word. That ended at Date and Time (Modified) – 2017:01:23 20:56:10. I know that because I took the picture below as I left the building and while Instagram6 doesn’t make that exif data easy to find I had it on the original which was copied to Flickr. It is strange to look at the texts and images as I was off in my memory by about 30-45 minutes the whole time.
![]()
After all that, the next steps are to write a new script that makes the structure from scratch and then look at patterned writing of content. Lots of time testing etc. We’ll see what that brings. I think it’ll be faster but I’ll report back on whether I’m right.7
1 Edification or amusement are optional.
2 Note actual screenshots from texts with my wife which indicate major plot points.
3 Sad trumpet music played.
4 My ability to estimate time and stick to promises to come home seems somewhat questionable in retrospect. Thankfully I have a very understanding wife.
5 I like to hyphenate-things. If it violates grammatical conventions simply re-read my work as free-verse poetry.
6 Still not a fan of their API limitations or the FB in general but I need to do more first-hand app use so I can speak from experience with regard to the interactions/expectations and then make websites (the web can do this!) that behave more like this.
7 Footnotes galore for those who like them, eh?