I still use Sublime when I’m not using VS Code. This isn’t the best idea but I do it anyway.
One of the things I like about both programs is being able to create little shortcuts to create code I write a lot. It speeds things up and makes me more consistent. Both programs let you do little tricks like writing a variable once in your snippet and having it appear multiple places. With a bit more work you can make that variable transform to save you even more time and be more consistent.
In this case, all I wanted to do is write my $1 variable in as a normal spaced and capitalized text and get a lowercase version with the spaces replaced by dashes in another area (what sanitize_title() does in WordPress land).
I could do either thing separately. I just couldn’t figure out how to do both.
I know some regex. It’s a lot like kind of knowing how to fly. I should probably work towards proficiency rather than half-knowing it and crashing all the time. I usually just stubborn and Google my way through it with Regex101 so I can see what’s going on. With the Sublime Snippet substitution pattern I was dealing with a Perl version of regex and some kind of Boost library that I still don’t know much about. I couldn’t figure out how to make a good testing environment for that.
Were it not for finding this Stackoverflow post, I’d never have figured this out.
The pattern makes sense eventually but there are lots of little errors you can make and no real way to see if you’re missing the capture or if the replacement is failing for some reason. It’s like when I did WordPress programming without var_dump and error logging everything. It’s pretty much the worst game of pin the tail on the donkey. The donkey is a ninja and the room is really big and full of broken glass. At least that’s what it felt like to me.
I’ll breakdown the value snippet substitution in the hopes it’ll stick in my head.
So the ${1/ portion is the initial variable that you’re typing in and on which all the actions will be performed.
Then you can do repeated capture groups inside () that are separated by | . . . so something like ${1/(capture1)|(capture2)|(capture3)
Then the action group is separated by a / and each action group is grouped inside (). Each one should start with a ? and the number of the initial capture group it’s referencing . . . so something like (?1 action)(?2 action)(?3 action).
Finally it ends with a / option like other regex.
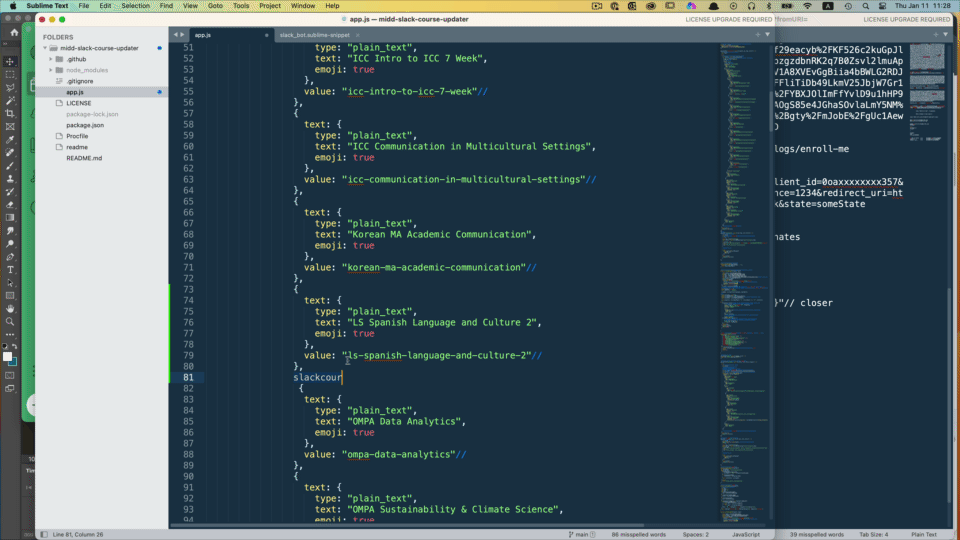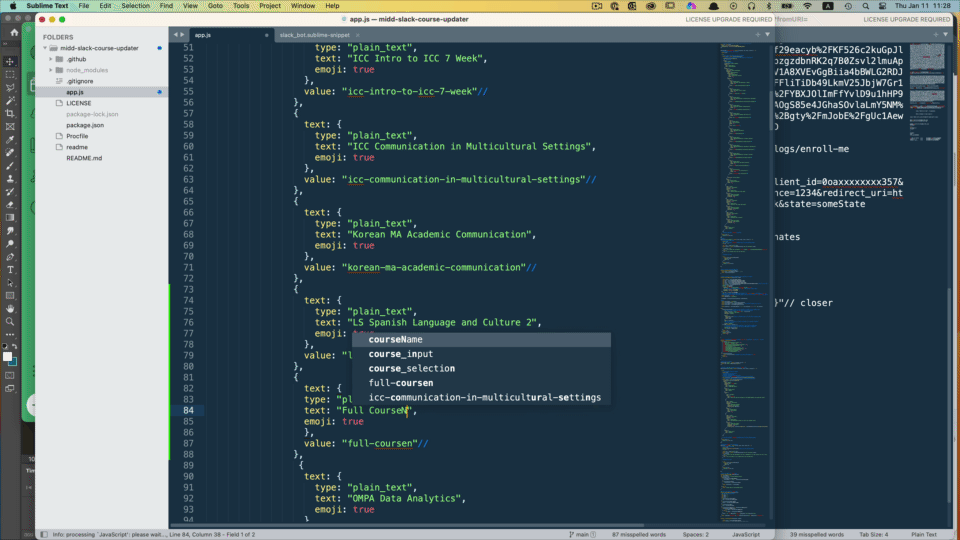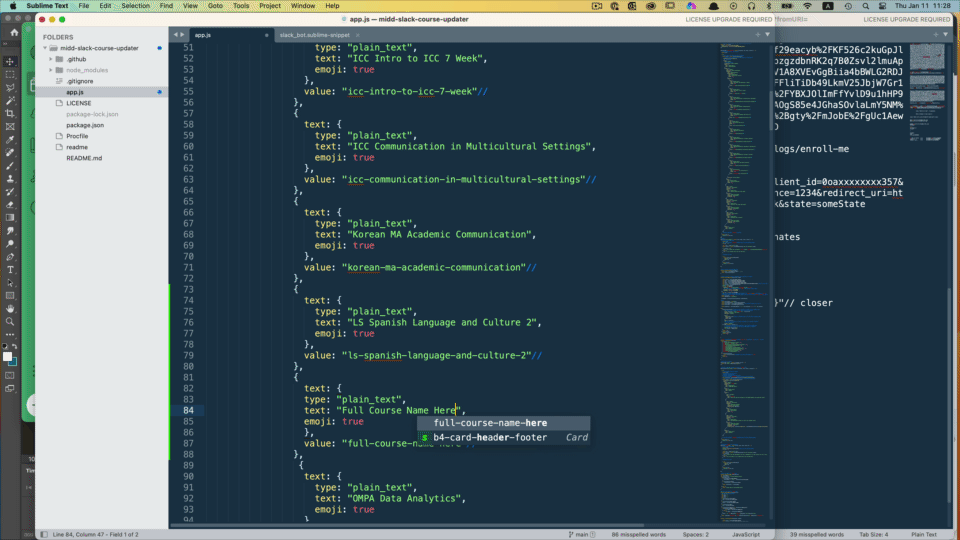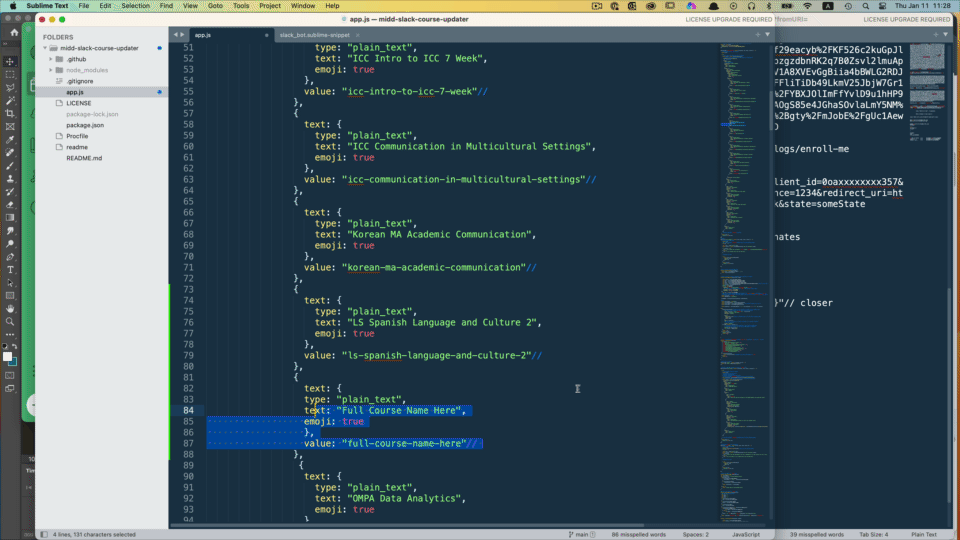
My snippet below allows me to type in a normal course name where the text element is and get the lowercase hyphenated version automatically in the value area.
<snippet>
<content><![CDATA[
{
text: {
type: "plain_text",
text: "$1",
emoji: true
},
value: "${1/([A-Z])|(?:( ))/(?1\l$1:)(?2:-)/g}"//
},
]]></content>
<tabTrigger>slackbot_course</tabTrigger>
<description>slack course</description>
<!-- Optional: Set a scope to limit where the snippet will trigger -->
<!-- <scope >source.python</scope > -->
</snippet>