This post is going to be a bit like my head- a jumbled mass of things that are interconnected in my head but may not make any sense to anyone else. But what else is a blog for but for getting a better idea of what’s in your own head?
Blogging in General
The group I’m a part of (ALT Lab) has been struggling with blogging for a while now. We were/are aiming for a post a week for each member of the group. It’s not easy for many of us.1 It’s a pattern I’ve seen with lots of organizations and lots of individuals. You’ll have the usual pattern that varies somewhere between not knowing what to say, not having anything worth saying etc. The end result is that people don’t write. If you talk to them they’ll have a million things that would be interesting to read and that would be “worth” sharing. Maybe not having time gets referenced but given it’s a desired piece of our work, that’s not our issue. It feels mainly like it’s a holdover from time in formal education. Writing ends up becoming something done for an omniscient expert who will pass judgement on thee. It happens to me at times- both time limits and wondering if there’s any audience or purpose to what I’m writing. Turns out I have 197 draft posts. A few of them will make it to published but it represents a chunk of stuff that ended being self-censored. I’ve been writing on this blog since 2006 so that’s not terrible but it probably means something. The only way around it I’ve found it is to keep putting content out for myself. I do refer to this site all the time for functional stuff but also to make connections between new and old thoughts. If I wrote for some general audience I wouldn’t be able to include a blog post about blogging. That kind of navel-gazing tends to make people nauseous.

In any case, I wrote it mainly because I really enjoy reading what people write and the recent posts from participants in the #IndieEdTech/API conversation at Davidson this past weekend have reminded me how cool it is to see people thinking. You’ll see some similar patterns in the writing but I think we end up looking at things in really different (but complimentary) ways. There are my old blog/real-life friends Jim, Alan,2 and Tim but I also had a chance to make connections with people like Adam Croom, Tim Klapdor, Kristen, Phil Windley, and a chunk of other people I need to re-track down.
The event was really interesting and was kicked off by a talk by Audrey Waters followed by an overview of the magic of APIs with Kin Lane. They’re both well worth checking out but, if you’re like me, take Audrey’s talk in carefully. She’s has a tendency to confirm my deepest fears and expand them a bit with well-founded reason and research. Actually, I urge equal caution with Kin as I’m now completely rebuilding workflows that I have had for years. It’d be enjoyable, but bad for my health, to have them as neighbors.
The rest of the time was spent in a “design sprint” led by Known‘s Erin Richey & Ben Werdmuller. I’d describe it as somewhat like the processes associated with understanding by design or UDL but with (many) more post-it notes and focused on a product of some kind. We were split into a couple of groups and got to work deciding what it was we wanted to build.
My group had an interesting mix of people. In addition to Kristin, Jim, we had some younger people in our group – two current students (grad and undergrad) and one recent graduate. They weren’t necessarily typical students but they were under 25 and school was a fresh/ongoing experience for them which is considerably better than most of these conversations normally get. It was also good they were around to help keep Jim on task.
We started by asking the students questions. I tried a few with idea (hope?) of using some API magic to reclaim the data they cared about from some den of corporate iniquity but . . . that held no interest to these students. Their most valuable online content . . . annotated PDFs in Mendeley, Instagram output this year- 3 pictures . . . more talking occurred. We eventually worked around to the idea that course descriptions don’t really help students know what kind of classes they were getting into. Was there a way to get at a truth deeper than course descriptions, than syllabi, than Rate My Professor, than even word of mouth could get to?3
It makes sense in lots of ways. I may not be a typical student but I’ve not chosen programs because of what I could see of the student work and I generally pass entirely if I can’t see any student work. I have to imagine some other people do that and that even more people would take advantage if it existed.
This concept also ties pretty tightly to something we’ve been trying to sketch out at VCU with the our Sociology department and one of their new online programs. I’ll describe what we’ve got as a functioning proof of concept currently and then see if I can adequately explain how the final envisioned product from the design sprint ends up diverging from this.
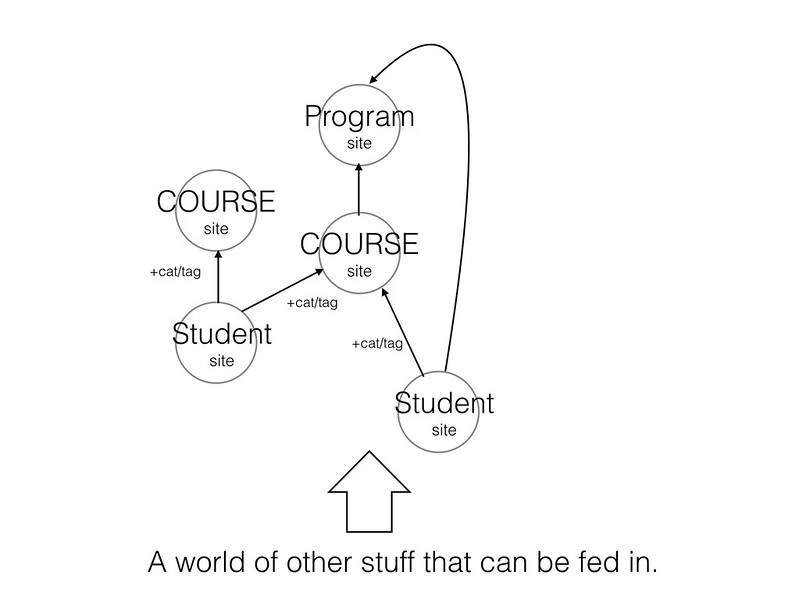
Consider this the idea of a portfolio that represents not just a student (a grad student in this case but applicable to undergrads as well) and their work but one that also represents the value a professor and the value of a program. Put the students in the front. Let their work speak for the program. More importantly, let changes in their work speak for the program. This would run contrary to the idea that a course is a course is a course because Sociology 101 with Jane Smith may be a very different experience than SOC 101 with Jane Doe and you’re going to see evidence of that in the student work. I see that as a feature. It might drive classes toward one another experience-wise but hopefully it’ll be an upward move.

On the API and ownership level, students could use their provisioned institutional sites (WordPress in this case) as a portal from other authoring environments into courses or they could write in the site itself. The institutionally provided student site would be the gateway into the system and would provide some standard options (maybe even the option to copy content written elsewhere for safe keeping). Those student sites aggregate to course sites which then feed into the program site. The program site allows people to see content created by students, as associated with courses, and associated with particular professors.
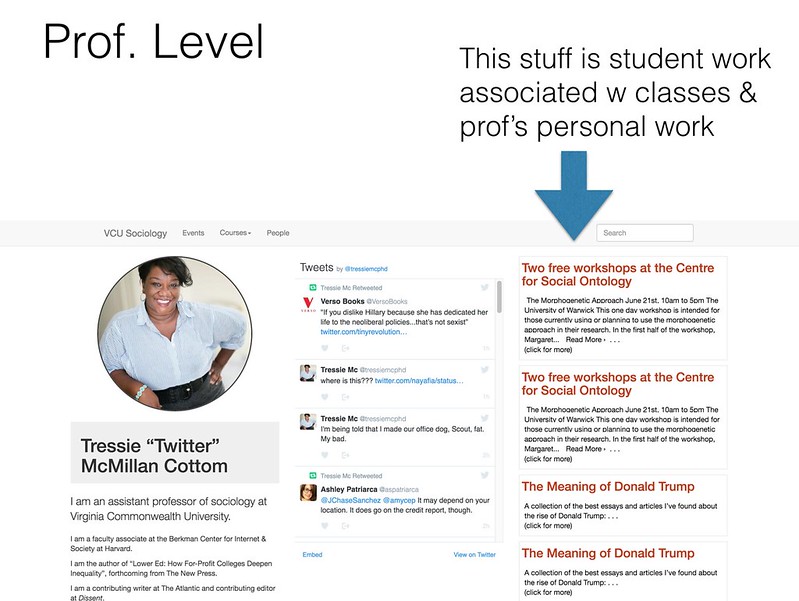
Mechanically it’s doing all this with RSS and a few categories and tags. It could just as easily be JSON or another option. You can play around with it a bit here. It is functional and that’s live data from open courses (though not necessarily the right data – for instance those aren’t Tressie’s courses but that is her Twitter feed). You could start to really streamline the metadata portion of this with a few simple integrations with an SIS or a basic plugin.
The design we ended up discussing took this concept and moved it a bit farther into the class comment/critique space. Students would have the ability to give feedback on the course and its impact on their learning but only in conjunction with their work from the class. The idea being that it provided “skin in the game” for course feedback and that you might be better able to judge the validity of student comment when seen in conjunction with their work.
API Shifts
Another portion of this conversation was APIs and a general idea around reclaiming your content from the various places you might have put it.
Get Flickr
I stayed up for a bit with Jim Groom one night messing with the Flickr API trying to figure out a decent way to grab all our Flickr photos and hand them over to S3. While we didn’t succeed that night, I think I ended up with a working script that downloads them and will make the S3 handoff once I pay for an account. So far, I’ve only run it on small batches but everything looks clean. When I do the final scenario, I’ll write up something more substantial.
No More IFTTT
After Kin mentioned that IFTTT, a service built from APIs, didn’t have an API . . . I began to look for ways out of that system. I’ve made some progress there.
I traded the RSS to Twitter Notification recipe for this Google SS version. I have a few more things on the list but progress is good.
Diigo to Pinboard
I have been duplicating my content from Diigo to Delicious and Pinboard since the last big Yahoo scare. Access to Diigo’s API costs money. I don’t use 90% of Diigo’s services and a number of them actually get in my way so I decided I’d move to Pinboard full time. The one thing I really wanted was the ability to do my weekly bookmark posts. I was able to grab the content I wanted (everything tagged ‘weekly’ for the last seven days) with this script. I then tried a plugin with a weekly schedule to create a post but messed up something significant and ended up with many duplicate posts in just a few short minutes. For now, I opted to go another route and just tied the script to a page and trigger it via cron. That’s over here if you want it. I’ll probably flip it to run off the v2 API in the near future but I just wanted to get something working.
Headless WordPress
Alan posted a link to HTML5Up templates in the #indieEdTech slack channel and on Twitter. I liked the templates and wondered how hard it’d be to setup the “headless” WP idea mentioned here. Turns out it was pretty easy. There are still a few bugs to work out but I took one of the templates, fed the JSON from v2 of the API into Angular and was able to have a working demo in an hour or so. Someone good could do it in a few minutes. I insisted on forgetting how much the order the javascripts load in effects things. The relevant chunks are below.
<form class="form-inline">
<input ng-model='search.title.rendered' type="text" placeholder="Filter by" autofocus>
</form>
</div>
<!-- Main -->
<div id="main">
<article class="thumb" ng-repeat="entry in entries | filter: search| orderBy:'entry.date'" >
<a href="{{ {entry.better_featured_image.media_details.sizes.medium.source_url }}" class="image"><img src="{{entry.better_featured_image.media_details.sizes.medium.source_url}}" alt="" /></a>
<h2 ng-bind-html="entry.title.rendered">{{ entry.title.rendered }}</h2>
<p>{{ entry.slug}}</p>
</article>
</div>
var app = angular.module('myApp', ['ngSanitize']);
//
app.controller('SuperCtrl', function($scope, $http) {
$http.get("http://bionicteaching.com/wp-json/wp/v2/posts/?filter[category_name]=photography&filter[posts_per_page]=30")
.success(function(response) {$scope.entries = response;});
});
'never accept, “The computer doesn’t work that way” as an answer
again.' #indieEdtech https://t.co/rU3BeU1PxL— Tom Woodward (@twoodwar) March 24, 2016
With all this, I start to take more control. I have more options. I can vary the post stems when I auto trigger Twitter notifications, I can change the HTML of the weekly bookmarks, I could blend other content into that page . . . It gets more and more interesting the more I can do.
Am I thinking differently?
I’ve been doing a lot more technical4 stuff for a while now. It’s been interesting because I’ve actively resisted any real scripting/programming for years while still doing programming-like things. For instance, avoiding regex and doing things in a Google Spreadsheet with formulas instead. Very similar patterns of thought but very different application environments (maybe differing levels of abstraction).5 I’m still not a serious programmer or, if such a thing doesn’t exist, then I’m certainly not an experienced programmer. I have a tendency to do all the things people6 say are bad ideas if you really want to learn programming – I tend to cut/paste from Stack Overflow/Github, I tend to use libraries/frameworks, I jump between languages/platforms/apis, I will settle for getting something done even if my understanding remains blurry, I remain someone vague on lots of core concepts . . .
I’m also participating in an FLC led by Andrew Ilnicki that is focused on VCU faculty who want to learn how to write HTML/CSS/Javascript. That’s giving me an interesting view on how this plays out with other adults who are delving into this stuff for the first time.
As I continue to learn more sophisticated programming, I think a lot about how it’s shaping my thinking. Do I think about things in the same way and apply those thoughts differently or am I actually coming up with new/different/more complex ideas because of what I now understand? It’s hard to tell.
I also wonder a lot about how I might share some of this with my own children and how someone might teach application of the thought patterns to others (with or without their expression as traditional programming). No real idea if I should even do this though. I usually hesitate before passing on anything in my head.
1 I make sure it happens through the weekly bookmarks summary and my weekly photography posts. Workflow + technology is how I try to deal with personal failings around organization and consistency.
2 Author of 75.8% of the comments on this site.
3 Maybe even better than those secret books of professors and all their tests that fraternities and groups like that keep.
4 It’s all relative.
5 Yes. You can use regex in Google SS. THERE ARE NO CLEAN LINES ANYWHERE!
6 some/many? at least some article I read once . . .
This is awesome. I started attempting to play with the Discogs REST API today to try to reclaim my record collection in the same fashion you are doing with Flickr. I am officially calling it and saying defeated (for now). I’ll have to pick your brain more. 🙂
For sure. You have a username/collection in there? I’m playing around a bit with it now and will try some stuff over the next few days if you want anything specific done.
Yep! I’ll publish a post soon on what I’m looking into but basically a card-like WP instance (similar to what you’re doing) that reclaims my collection as (Im assuming) a custom post type. https://www.discogs.com/user/acroom/collection . API doesn’t pull images but I’m ok with that as it will give me a reason to take more photos anyways.