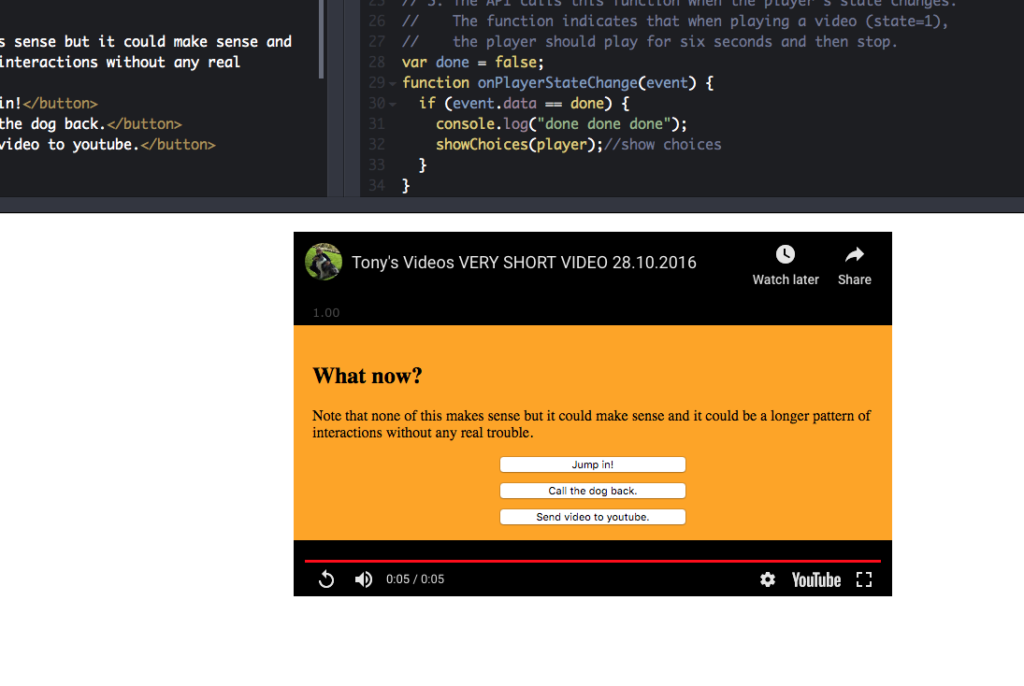
This was a quick demo built to show how we could mix videos hosted on YouTube with viewer choices at the end of those videos that cause other videos to load. There’s a bit of work around what the visuals would be like for a user but nothing aggressive.1 If you play the first video […]
Read More… from YouTube Choose Your Own Adventure Interaction
