The Context
Middlebury has an interesting setup. They call them Go Links. It’s basically a version of tinyURL that anyone at Middlebury (students included) can use to make customized Middlebury links. If you’re on campus, you can use go/whatever and off-campus you have to use go.middlebury.edu/whatever.1 This replaced a giant redirect list. I’m not sure how I feel about it. In some ways it’s kind of fun and useful but it feels like it creates considerable technical2 debt in the long run. It also habituates people to getting to things in ways that require rethinking outside of the campus network. I also don’t know how you end up removing these when the students graduate or when the usage dies out. I guess you’d do something around tracking usage and auto-deleting after a certain period of inactivity. Otherwise this just grows forever. I don’t think you want this chart to keep going up. There are currently 1,144 entries that start with C. That includes links like critical-conversation, critical-conversations, criticalconversation, criticalconversations . . . so you can see how this plays out. I found the statement below as I delved a bit deeper into the system. It’s a tricky spot. Go Links are something that faculty and students expect and use. I can’t help but see them as an ever-growing layer of possible problems without a whole lot of major benefits. I also know that is how some people see/saw3 Ram Pages and the ever growing number of sites. No easy answers but always better to start with a plan and a rationale for your plan.
There are several thousand existing GO shortcuts with no one to take care of them! If you requested one of these, or believe that you are the best person to manage the shortcut, please contact the Helpdesk (submit a ticket). We’ll set you up as the manager of that shortcut so that you can edit its description and update its URL, if needed.
The Work
In preparation for the Fall, we were checking out the go links that had Canvas in them or at least those that start with C. What I needed to do was get from this index to a spreadsheet that had the Go Link, the real link, and the person/people in charge of the link so we could decide what might need deleting.
Step 1
I just copied and pasted the links starting with Canvas into a Google Sheet and deleted the ones I didn’t need. Sometimes it’s not worth automating something.
Step 2
I now have a bunch of go/whatever in column A. The data I want is on the linked information page. That page gives me the real URL and the link owner(s). The pattern to get to that page is http://go.middlebury.edu/info.php?code=whatever. So I can get the code portion I need from go/whatever by =right(A1,LEN(A1)-3) which just cuts off the first 3 characters (go/). Then I can just staple it on to the url pattern like so =CONCAT(“http://go.middlebury.edu/info.php?code=”,B1)
Step 3
Now to actually do the useful part. We’re going to use IMPORTXML to get the content we need into the spreadsheet. This uses XPATH to get the pieces we want from the URL. The easiest way I’ve found to do this with more complex paths is just to use Chrome’s inspector and use the Copy Xpath option.
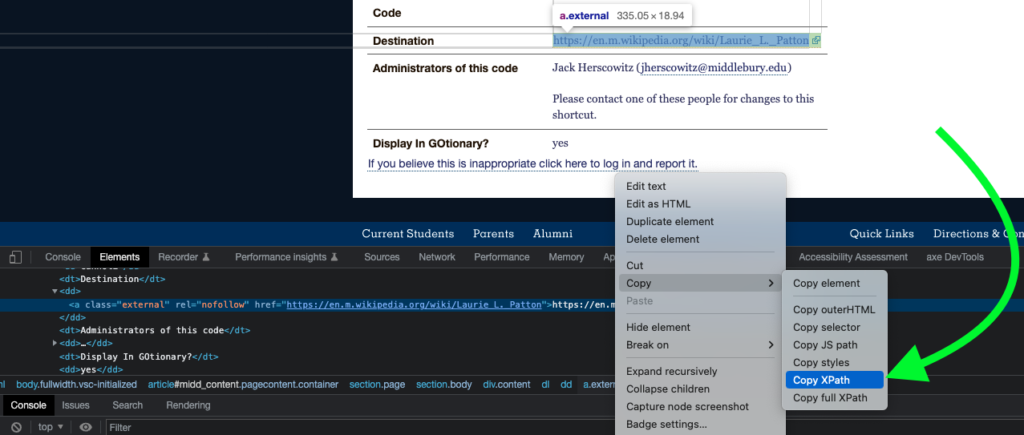
This lets up use a function that uses the URL from the last step in combination with the xpath we copied to get IMPORTXML(C2,”//*[@id=’midd_content’]/section[2]/section/div/dl/dd[3]”). Pretty immediately one hassle that pops up is that if there are multiple owners, then they go into individual columns. That’s nice sometimes but not in this case. Luckily, I can modify that into a single string using JOIN. Now our function looks like =join(” – “,IMPORTXML(C1,”//*[@id=’midd_content’]/section[2]/section/div/dl/dd[3]”)). There was some variance there where some of the page has an extra dd but all I had to do was change the xpath 3 variable to 4.