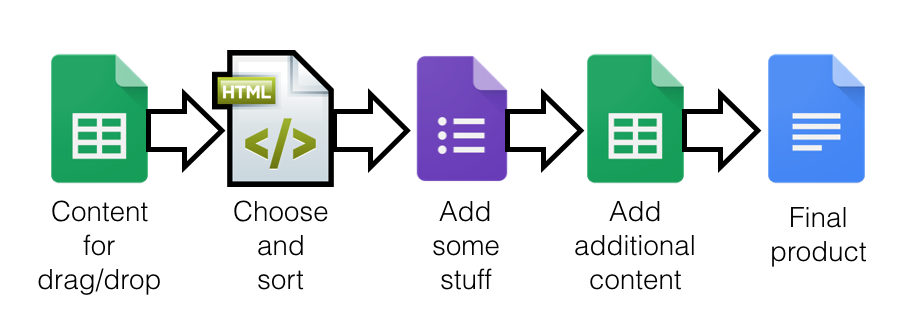
Image from page 60 of “Children’s ballads from history and folklore” (1886) flickr photo by Internet Archive Book Images shared with no copyright restriction (Flickr Commons) Driven mad by curiousity after this Matthew Baldwin tweet, I built this little thing. It uses the amazing Martin Hawksey’s TAGS for gathering the Tweets in Google Sheets and […]
Trump Dump Data & Playing with TAGS