Way back in the dawn of time (2009), I was more tightly integrated into a unit that was more focused on staff development writ large. We had experiences, trainings, and professional growth.I’ve thought about those three categories of offerings quite a bit since then. With some slight tweaks, I feel like they apply well to […]
Category: Possibilities
Can you beat the LLM?
I was curious how well the AI would do at creating sentences that were the opposite of what I wrote. I wanted full opposite-ness, as much oppositeness as I could get. If I type in “The black cat sat.” I’d want something like “A white dog stood.” With my admittedly minimal effort, I got minimal […]
It’s a small, open world
. . . at least some of the time. At a recent basketball game for one of my children, a fellow parent whom I have spoken to a number of times over the years said “Hey, I saw one of your pictures in a presentation I was watching yesterday.”1 He described one of the images […]
Bending it in the browser
I was listening to the Shop Talk Show episode on patching the web. They mentioned removing the trending tweets sidebar and it reminded me to do that. I had to look up aria label selectors in CSS, but applying this bit of CSS using Stylebot removes it nicely. Digital fluency/Anti-app rambling I couldn’t do that […]
Domain of One’s Own – Initial MiddCreate Conversation
Yesterday we had our first group meeting revisiting where we wanted MiddCreate to go. That’s one of my main projects so I was facilitating the meeting. It was a bit odd to start a big project like this over Zoom but I think it went ok. I set up a Google Doc as a way […]
Read More… from Domain of One’s Own – Initial MiddCreate Conversation
VCU: The Long Goodbye (Art)
Man. These are taking some time to write and I know I’m missing all kinds of stuff. I really have to think through how to do this better for the future. I also found out VCU turned off the Google Takeout option so there’s no easy way to archive my mail or get anything else […]
VCU: The Long Goodbye (AFAM and ANTH)
Here’s another stuff-I-did-in-the-past post. It may be doing this does a couple things for me. Whenever I’ve entered a new job I have felt like a moron who knows nothing desperately trying to show I know something and am useful without coming off as desperate.1 Trying to make new friends while learning new acronyms and […]
Recent Work – End of June Edition
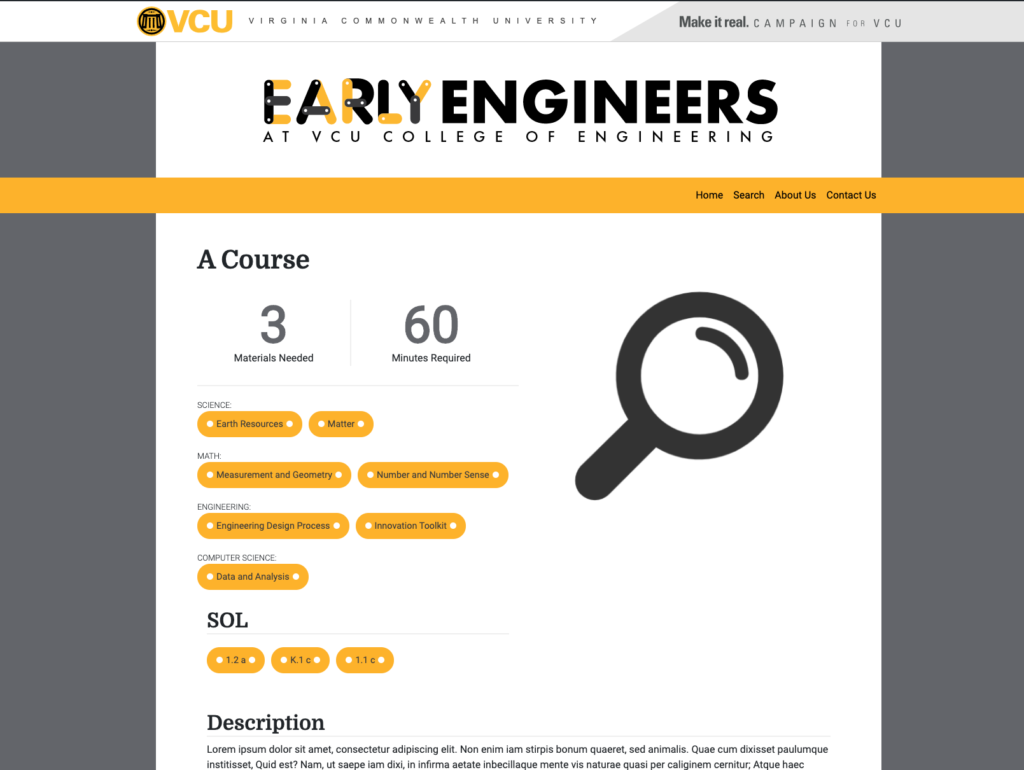
Greetings dear reader. I write to you again out of the desperate hope that writing this cements things I’ve learned better in my own head and maybe gives a person out there something that saves them some time or suffering or maybe just provides a kernel of an idea that they can improve on. That’s […]
Gravity Forms + Mermaid JS = Decision Flowcharts
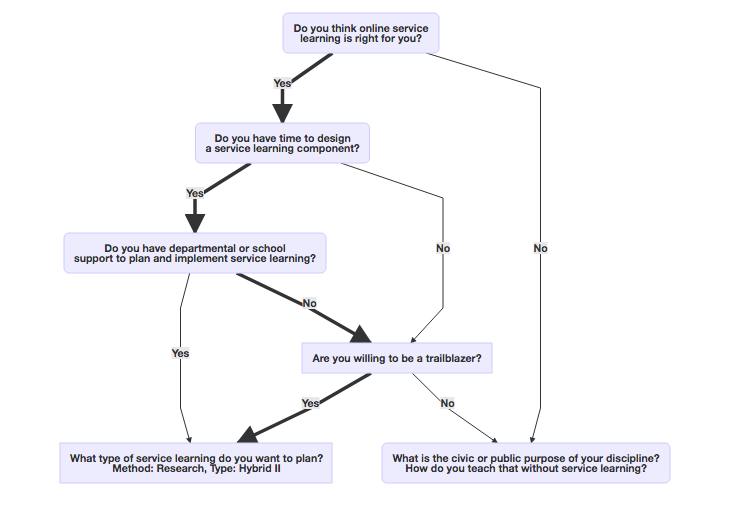
I was building something in JSPlumb the other day1 and it prompted Tim to ask if we could build flowcharts based on survey responses so that respondents could see their choices in context. I thought we could and it led to this simple example2 that I think will have lots of interesting and broad applications […]
Read More… from Gravity Forms + Mermaid JS = Decision Flowcharts
Tweets as Presentation: Reflecting on #pressedconf18
I took the opportunity to participate in the #PressedConf yesterday. Described as “. . . a twitter conference (#pressedconf18) looking into how WordPress is used in teaching, pedagogy and research.” it was a pretty impressive number of people and topics covered on Twitter in roughly 20 minute “Tweet storms.”1 Presenting on Twitter was something new […]
Read More… from Tweets as Presentation: Reflecting on #pressedconf18